Pipelining
Pipelining is an implementation technique where multiple instructions are overlapped in execution. The computer pipeline is divided in stages. Each stage completes a part of an instruction in parallel. The stages are connected one to the next to form a pipe - instructions enter at one end, progress through the stages, and exit at the other end.
Datapath instruction:
R-type
J-type
5 Component of computer.
▸ Processor (CPU): the active part of the computer that does all the work (data manipulation and decision-making)
▸ Datapath: portion of the processor that contains hardware necessary to perform operations required by the processor (the brawn)
▸ Control: portion of the processor (also in hardware) that tells the datapath what needs to be done (the brain)
5 Stage of Datapath
▸ Stage 1: Instruction Fetch
▸ Stage 2: Instruction Decode
▸ Stage 3: ALU (Arithmetic-Logic Unit)
▸ Stage 4: Memory Access
▸ Stage 5: Register Write
Stage 1:
Instruction Fetch. there are no matter what the instruction, the 32-bit instruction word must
first be fetched from memory (the cache-memory hierarchy) it also, this is where we Increment PC (that is, PC = PC + 4, to
point to the next instruction: byte addressing so + 4)
▸ Stage 2:
Instruction Decode. upon fetching the instruction, we next gather data from the
fields (decode all necessary instruction data) .First, read the opcode to determine instruction type and field
lengths ,second read in data from all necessary registers
▸ for add, read two registers ; for addi, read one register
; for jal, no reads necessary
▸ Stage 3:
ALU (Arithmetic-Logic Unit). The real work of most instructions is done here: arithmetic (+,
-, *, /), shifting, logic (&, |), comparisons (slt).. loads and stores?
▸ lw $t0, 40($t1) the address we are accessing in memory = the value in $t1
PLUS the value 40
▸ Stage 4: Memory Access . Actually only the load and store instructions do anything during
this stage; the others remain idle during this stage or skip it all
together ,since these instructions have a unique step, we need this extra
stage to account for them ,as a result of the cache system, this stage is expected to be fast
▸ Stage 5: Register Write. Most instructions write the result of some computation into a
register Examples: arithmetic, logical, shifts, loads, slt .. Stores, branches, jumps don’t write anything into a register at the end
▸ these remain idle during this fifth stage or skip it all together .
Steps Of Datapath
Datapath walkthrough
add $r3, $r1, $r2 # r3 = r1 + r2
▸ Stage 1: fetch this instruction, increment PC
▸ Stage 2: decode to determine it is an add, then read registers $r1 and $r2
▸ Stage 3: add the two values retrieved in Stage 2
▸ Stage 4: idle (nothing to write to memory)
▸ Stage 5: write result of Stage 3 into register $r3
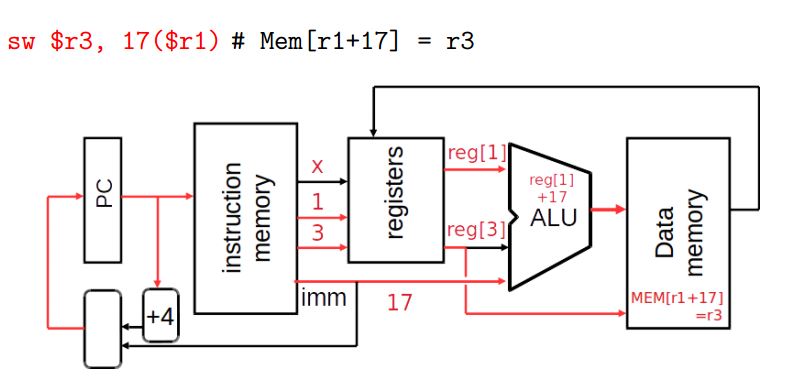
sw instruction
sw $r3, 17($r1) # Mem[r1+17] = r3
Stage 1: fetch this instruction, increment PC
Stage 2: decode to determine it is a sw, then read registers $r1
and $r3
Stage 3: add 17 to value in register $r1 (retrieved in Stage 2)
to compute address
Stage 4: write value in register $r3 (retrieved in Stage 2) into
memory address computed in Stage 3 Stage 5: idle (nothing to write into a register)
Before pipeline..
• Single-cycle control: hardwired
– Low CPI (1)
– Long clock period (to accommodate slowest instruction)
• Multi-cycle control: micro-programmed
– Short clock period
– High CPI
Pipeline
• Start with multi-cycle design
• When insn0 goes from stage 1 to stage 2
… insn1 starts stage 1
• Each instruction passes through all stages
… but instructions enter and leave at faster rate
Pipeline Terminology
• Pipeline Hazards
– Potential violations of program dependencies .Must ensure program dependencies are not violated
• Hazard Resolution
– Static method: performed at compile time in software .Dynamic method: performed at runtime using hardware
– Two options: Stall (costs perf.) or Forward (costs hw.)
• Pipeline Interlock
– Hardware mechanism for dynamic hazard resolution
– Must detect and enforce dependencies at runtime